
From the start let me say that there is no right or wrong way to perform a Surname Study (One Name Study). What works for me may not work for you. I make several comments in this article about Robin Firth as he has published a similar article and what works for him does not work for me, this is not a criticism of his approach it is just I do things differently.
There are many reasons for conducting a Surname Study, one of the most common is to knock down a ‘brick wall’. This is where you cannot find a birth record for an individual but there are several possibilities and each needs to be researched until you find the correct ancestor. This is often made more complicated where you find several people with the same name in the same location at the same time and you need to find which is ‘yours’. Another common reason for doing a Surname Study is purely for the research and to find out more about the name.
I fall into the second category, after researching my direct ancestors for over 25 years I had gathered as much information as I wanted on my ancestors. Although from time to time I still re-visit my ancestral research to find out if there is any new information available to help me understand what their lives were like. I decided that I wanted to continue doing genealogical research, my paternal grandmothers maiden name was Lefever, being a relatively uncommon name in the UK, I decided to study this surname.
Unlike Roger Firth (http://www.firthworks.com/genealogy/NorthernFirths/RRR/index.html This link now updated) I am not interested in just collecting a large database of names, my aim is to construct families and to find out all I can about an individual as I find their life stories makes the research interesting for me.
Recording Data
I use Family Historian to store my data locally, like Roger I do not make my data available on any of the online genealogy sites. With local storage I can ensure data integrity by controlling what data is entered into my records.
I record all the data as entered in the original record that I am looking at I do not normalise it. I think that it is very important to record what is actually written, that way if I am contacted by somebody looking at the same record we are seeing exactly the same thing. There are several different ways of spelling my maternal grandmothers surname and she used two of them during her lifetime both Lefever and Lefevre. By using Family Historian, I can use its inbuilt facility to record both surnames, some people change their first names or start using their middle name instead of their first name and I think it is important to record this too.
Recording all name changes was particularly relevant when I was contacted by a Lefever researcher recently she asked about her grandfather whose surname was recorded as Le Feuvre. I have only found this spelling of the surname from residents of the Channel Islands. I have the majority of the Channel Islands name bearers recorded and could not find him in my records. On speaking further with the enquirer I eventually traced her grandfather in my English records, he had changed his surname spelling in his teens from Lefever to Le Feuvre, all his later records used this spelling.
I am conducting a worldwide study into the Lefever surname and currently have details of name bearers in 17 countries. Family Historian is capable of handling many thousands of records and still remain performant, however, my choice is to have a separate Family Historian project for each country. This is against the general advice that is generally given in the Family Historian Users Group (FHUG). Going back to the start of this article where I said ‘what works for me may not work for you’ this is an example of the way that I prefer to work. My main reason for working in this way is to more easily find and individual that I already have in my records by breaking the search down to smaller chunks of data. This is particularly relevant where you already have data on an individual and then find a new record that may refer to someone you already have data on. To make searching for existing individuals in my Family Historian database I have added additional columns to the Records window. This is easy to do and this is what my records window now looks like:
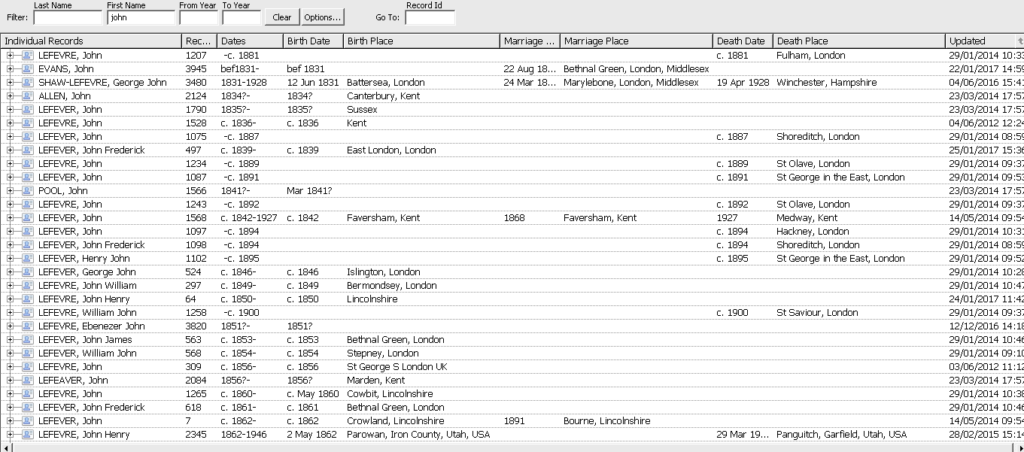
By adding the date and place for each of the BMD events I can sort into ascending or descending order on any of the columns and then use the filter to find the first name of the individual I am looking for. In the screenshot above you can see I have searched for a first name of John and I can now more easily find the John that may be referred to in the new record that I have found. This is particularly useful if you have lots of individuals, as I have, with common first names.
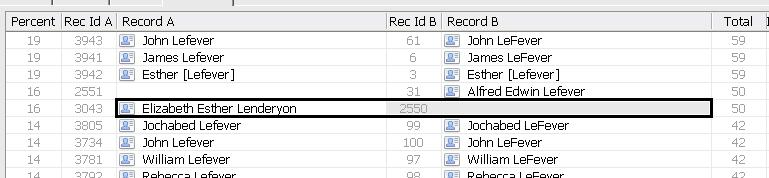
If I cannot find a definitive match using this approach I then create a new individual with the new record details for them and their family if appropriate. Every few sessions of running Family Historian I run the ‘Find Duplicate Individuals’ plugin on the database to see if there are any suggested matches. As is shown in the below screenshot there are several potential matches in this database:
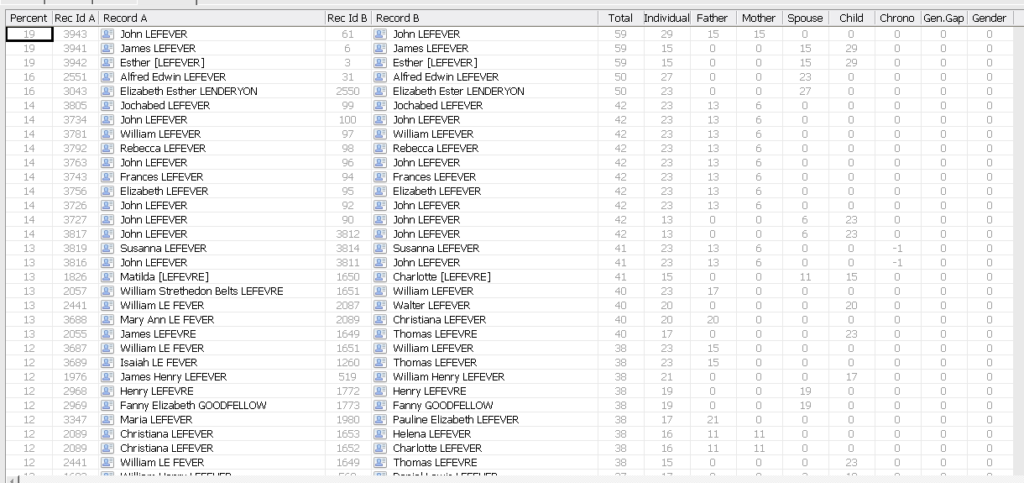
If you left click and then shift left click on the second record both are highlighted and then from the Edit menu select Merge/Compare Records and then adjust what to keep/discard/merge. If there is a family involved, then cancel the individual merge and merge the family instead. If you look at the below screenshot the reason for the two initial records is the different spellings of Elizabeths’ middle name.
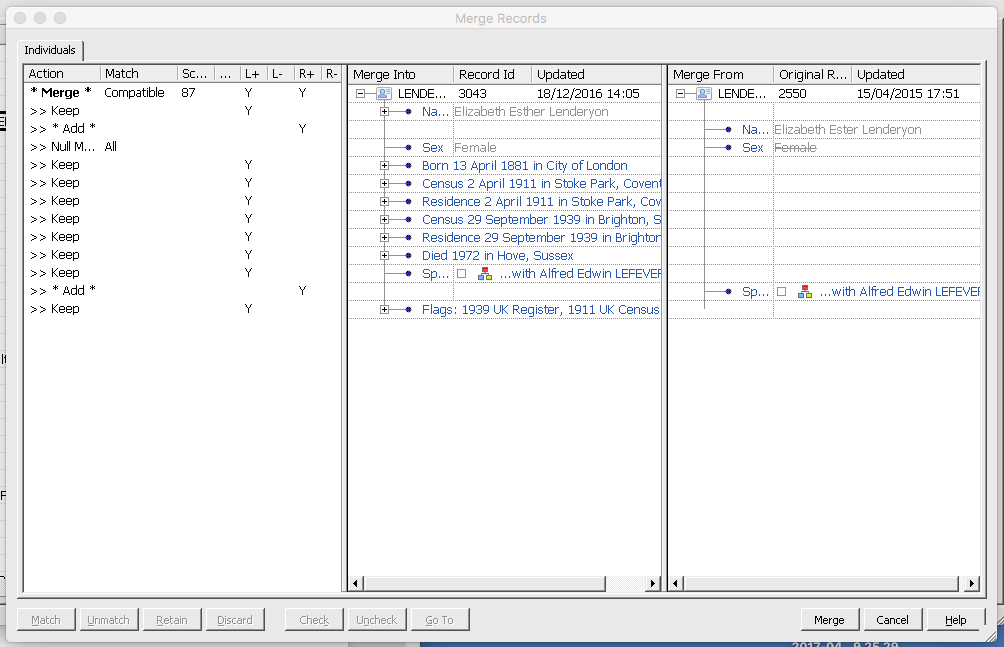
Here I have changed to the family window as I want to merge the two Alfred Edwin Lefever entries too. I have switched to the Family records window and in the filter I have started to type Esther just with the 3 first letters and the two family records I am interested in are shown. Now I need to select these two family records and merge them.
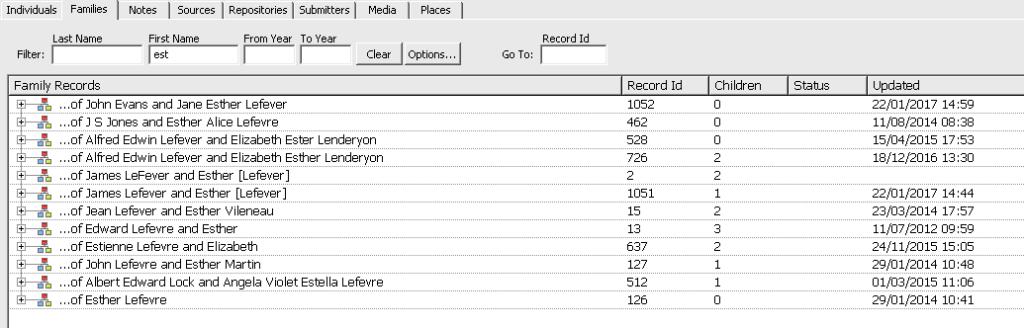
If you now go back to the Find Duplicates resultset you will see that both of the duplicate individuals from this marriage are now missing.
Research
Once a female marries and changes her name I no longer record any details of her. When a woman marries a Lefever male and where I don’t know her maiden surname I record her as a Lefever in square brackets and so she is displayed as, for example, Esther [Lefever]. The usual reason for her surname being unknown is when I find her as the wife of a Lefever in a census record.
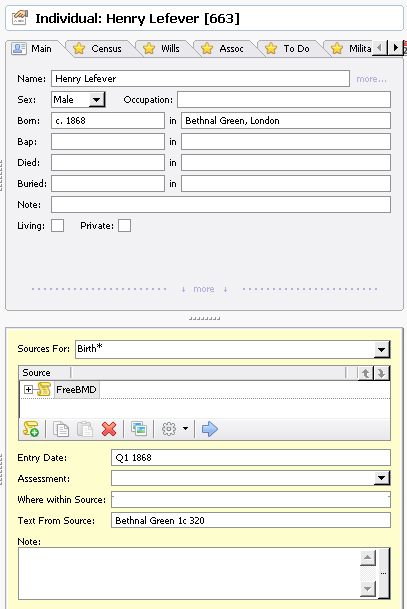
I make full use of Ancestral Sources wherever possible to record all the details of the event record that I have found. I also record an image of the record if it is available and this is stored in the usual way by Family Historian. I use ‘method 1’ for all my census, birth, christening, marriage, death and burial records where I have full information. Where I just have a GRO reference to a certificate I use ‘method 2’ and have a generic source for the repository. Where I don’t have exact dates for an event I use the circa date functions within Family Historian. This is an example of how I record the GRO birth information for an individual.
Where I have, for instance a second spouse, I record the date of death as before the date of the second marriage if the event was in the 1800’s. As I get further into the 20th century I will have to revisit this approach as divorce becomes more common. This approach does give a reasonable approximation and helps to find missing death registration details.
Unlike Roger I do not normalise location data. I record what is written in the record. I think that this is important particularly as towns get moved between counties in the UK not infrequently. An example of this is Bournemouth, when I lived there it was in Hampshire but in April 1974 it was moved to become part of Dorset. For a researcher who is unfamiliar with the UK and the change in county boundaries they may well think that Bournemouth, Hampshire and Bournemouth Dorset are two separate places.
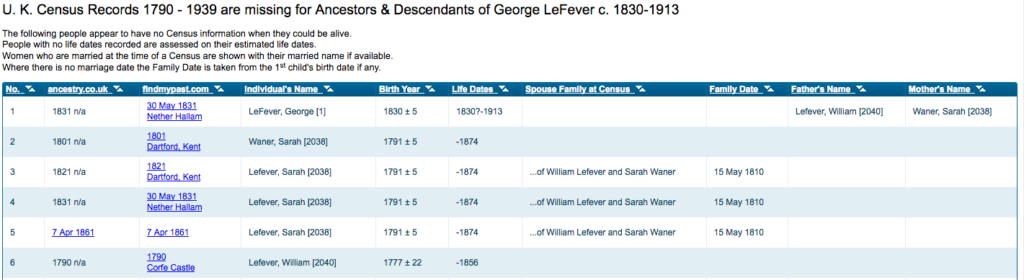
Another very useful plugin for Surname Studiers using Family Historian is the ‘Lookup missing census facts’ plugin. This gives the report below with links to potential records in the various online sites such as Ancestry and FindMyPast.
The similar plugin ‘Lookup missing BMD facts’ is also useful, if like me, you want to record all the information about an individual.

There are many other plugins available for Family Historian, some you may find more useful than me when researching your surname. It is well worth the time to read the information about each of them in the plugin store to find out if they will be of benefit to you.
Displaying your research results.
The reports and charts from Family Historian are reasonable for the display of your data and they can be improved by following the advice on the FHUG forum and Knowledgebase. You can also save the Family Historian report in Rich Text Format and then edit it in a word processing programme. There are some other reporting options available such as The Complete Genealogy Reporter and for charting there is the Progeny Charting Companion.
Family Historian will create a static website for you from your data and the website produced can then be edited and adjusted to suit your style. The data can also be exported to dynamic website creators such as TNG or Genealone. There is an enhanced Gedcom export plugin available that provides an export file suitable for many different sites.
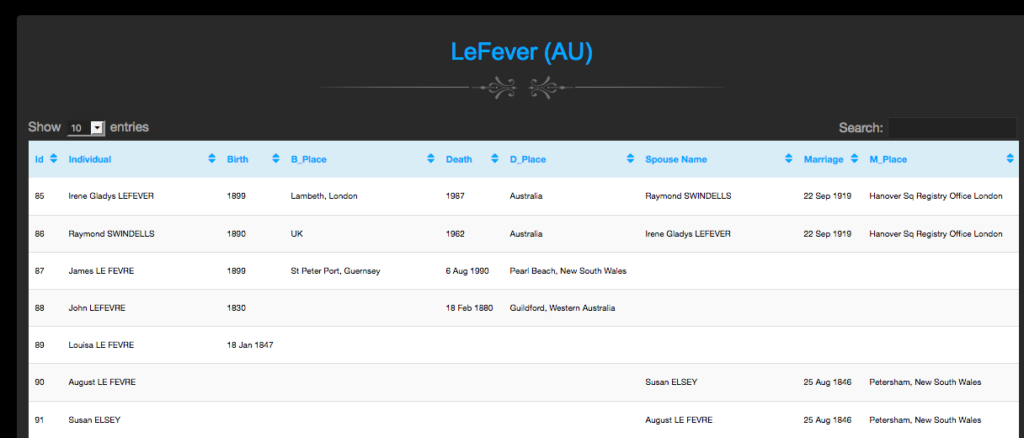
I do not publish the full details of my research online as I wish researchers to contact me so that we can pool information on the person(s) they are interested in. I therefore just publish the BMD date and place information on my website and ask for them to contact me for more information. I make use of a custom query in Family Historian to export a CSV file of this data that I can then import into my website. This is what I display:
Conclusion
As I said at the beginning of this article there is no right or wrong way to carry out a Surname Study, this is the way that I do it.
Should you wish to contact me about this article please use the contact page.
Resources
| Family Historian website | http://www.family-historian.co.uk/ |
| Family Historian Users Group (FHUG) | https://www.fhug.org.uk/ |
| The Surname Society | http://surname-society.org/ |
| The Complete Genealogy Reporter | http://www.tcgr.bufton.org/ |
| Progeny Charting Companion | https://progenygenealogy.com/ |
| Ancestral Sources | http://www.ancestralsources.com/ |